The project I am working on allows users to create Stock Screeners based on both technical and fundamental criteria. Stock Screeners are then "backtested" by simulating the results of applying in over the last 10 years using Point-in-Time data. I get back the list of trades and overall graph of performance. (If that is unclear, I have an overview here and there with more details).
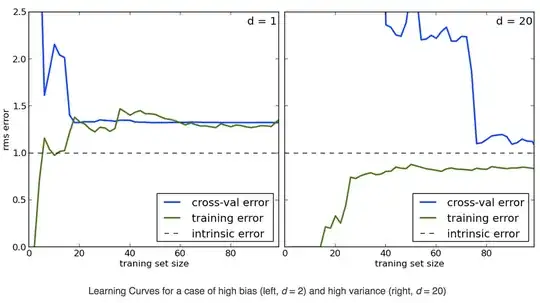
Now a common problem is that users create overfitted stock screeners. I would love to give them a warning when the screen is likely to be over-fitted.
Fields I have to work with
- All trades made by the Stock Screener
- Stock, Start Date, Start Price, End Date, End Price
- S&P 500 performance for the same time frame
- Market Cap, Sector, and Industry of each Stock