You can find below a worked out example (on a univariate version for the temperatures attribute) which, using statsmodels ARIMA, does not even finish the excution after hours trying for it.
An option you have regarding the performance issues is to actually use another efficient library like Keras with Tensorflow modelling an LSTM useful for time series data, which is capable of dealing with so many samples without performance issues.
This dataset contains 420551 samples, which is very costly with the ARIMA statsmodels approach via walk-forward validation...
You can extract the temperature values for carrying out the univariate time series forecast.
See below an example (based on this tutorial) where leaving hyperparametrization aside for now, you can train a nearly half a millon time series samples without performance issues (you can try on google colab for faster checks for free).
From the example in the tutorial, you should pay special attention at:
- the way the data is splitted:
def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
Reshape data from (history_size,) to (history_size, 1)
data.append(np.reshape(dataset[indices], (history_size, 1)))
labels.append(dataset[i+target_size])
return np.array(data), np.array(labels)
where, using 20 samples as recent history to predict the next value you can use:
univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT,
univariate_past_history,
univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,
univariate_past_history,
univariate_future_target)
having something like:
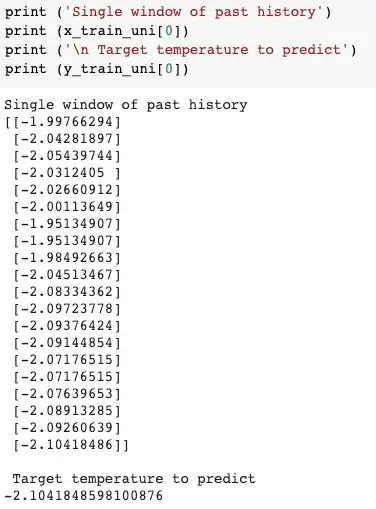
the way the model is defined:
simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]),
tf.keras.layers.Dense(1)
])
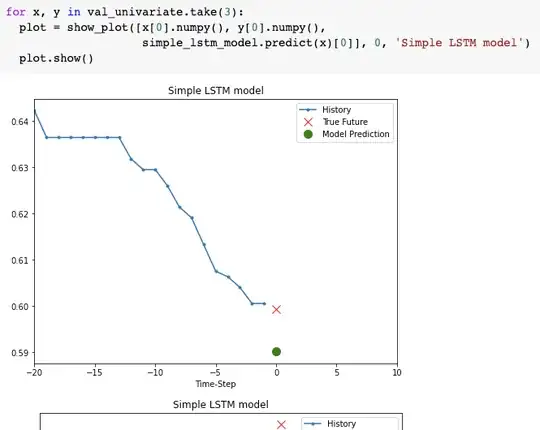
which comparing to a baseline model by predicting simply the mean of the history values, you have:
- baseline model predicting based on simply the mean of past values:
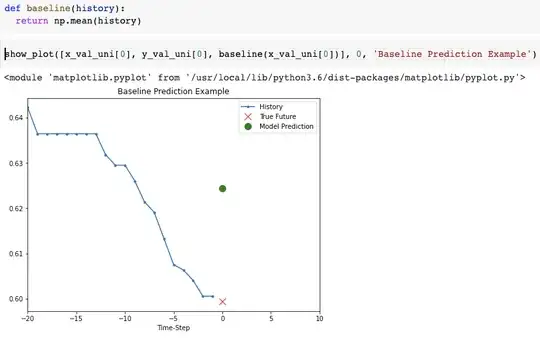
VS
- predicting wih the trained LSTM model: