For an MSE Loss, you will have a convex surface
Gradient Descent on a convex function is guaranteed to converge if the learning rate is not too high. The only that can happen is a high enough learning rate which diverges the learning
Impact of one record per learning step - Light on computing but a zigzag gradient
Working on a single instance at a time makes the algorithm much faster because it has very little data to manipulate at every iteration.
On the other hand, due to its stochastic (i.e., random) nature, this algorithm is much less regular than Batch Gradient Descent: instead of gently decreasing until it reaches the minimum, the cost function will bounce up and down, decreasing only on average.
$\hspace{2cm}$[Ref] - Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow,by Aurelien Geron
Impact of multi-variate gradient -
Multi-variate means, now you have multiple participants to decide the resultant Gradient. Everything will be the same and the learning will follow the net Gradient path.
One thing that will change is that with a high dimension, we have a long and flat surface in most of the places in the Loss space which can slow down the learning if the learning rate is not scheduled. Convergence is still guaranteed if LR is not too high.
For Intuition -
For more than 3-D, you will have to trust on the extrapolation and vizualize in your own way.
$\hspace{3cm}$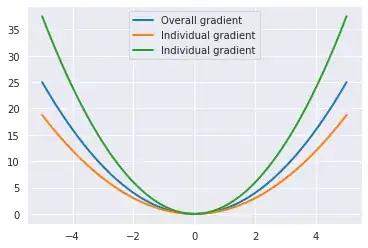
$\hspace{3cm}$Individual record Gradient and Overall gradient - 1 Feature
$\hspace{3cm}$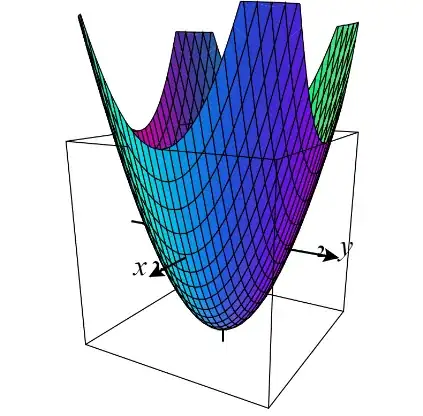
$\hspace{6cm}$A Loss surface in 3-D - 2 Features
$\hspace{3cm}$[3-D plot credit] - https://www.monroecc.edu/faculty/paulseeburger/calcnsf/CalcPlot3D/

