I have 40000 rows of text data of health care domain. Data has one column for text (2-5 sentences) and one column for its category. I want to classify that into 300 categories. Some categories are independent while some are somewhat related. Distribution of data among categories is not uniform either i.e some of the categories(around 40 of them) have less data about 2-3 rows.
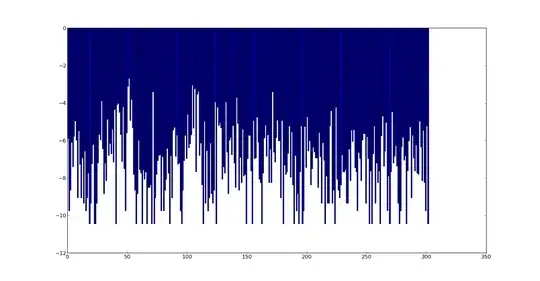
I am attaching log probablity of each class/categories. (OR distribution of classes) here.