I have a load of documents, which have a load of key value pairs in them. The key might not be unique so there might be multiple keys of the same type with different values.
I want to compare the similarity of the keys between 2 documents. More specifically the string similarity of these values. I am thinking of using something like the Smith-Waterman Algorithm to compare the similarity.
So I've drawn a picture of how I'm thinking about representing the data -
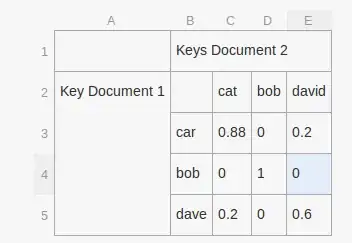
The values in the cells are the result of the smith-waterman algorithm (or some other string similarity metric).
Image that this matrix represents a key type of "things" I then need to add the "things" similarity score into a vector of 0 or 1. Thats ok.
What I can't figure out is how I determine if the matrix is similar or not similar - ideally I want to convert the matrix to an number between 0 and 1 and then I'll just set a threshold to score it as either 0 or 1.
Any ideas how I can create a score of the matrix? Does anyone know any algorithms that do this type of thing (obviously things like how smith waterman works is kind of applicable).