I have a doubt regarding the cross validation approach and train-validation-test approach.
I was told that I can split a dataset into 3 parts:
- Train: we train the model.
- Validation: we validate and adjust model parameters.
- Test: never seen before data. We get an unbiased final estimate.
So far, we have split into three subsets. Until here everything is okay. Attached is a picture:
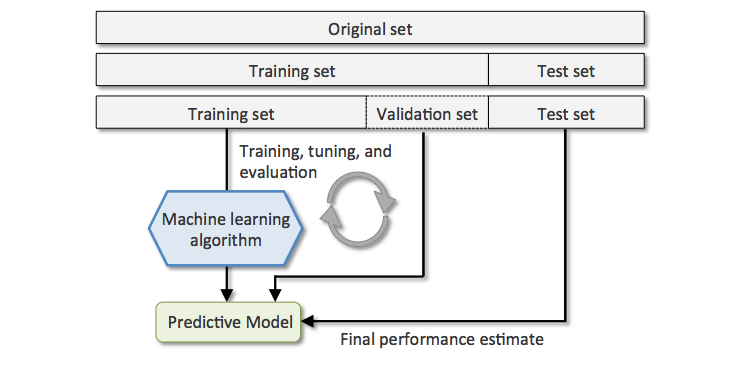
Then I came across the K-fold cross validation approach and what I don’t understand is how I can relate the Test subset from the above approach. Meaning, in 5-fold cross validation we split the data into 5 and in each iteration the non-validation subset is used as the train subset and the validation is used as test set. But, in terms of the above mentioned example, where is the validation part in k-fold cross validation? We either have validation or test subset.
When I refer myself to train/validation/test, that “test” is the scoring:
Model development is generally a two-stage process. The first stage is training and validation, during which you apply algorithms to data for which you know the outcomes to uncover patterns between its features and the target variable. The second stage is scoring, in which you apply the trained model to a new dataset. Then, it returns outcomes in the form of probability scores for classification problems and estimated averages for regression problems. Finally, you deploy the trained model into a production application or use the insights it uncovers to improve business processes.
As an example, I found the Sci-Kit learn cross validation version as you can see in the following picture:

When doing the splitting, you can see that the algorithm that they give you, only takes care of the training part of the original dataset. So, in the end, we are not able to perform the Final evaluation process as you can see in the attached picture.
Thank you!
