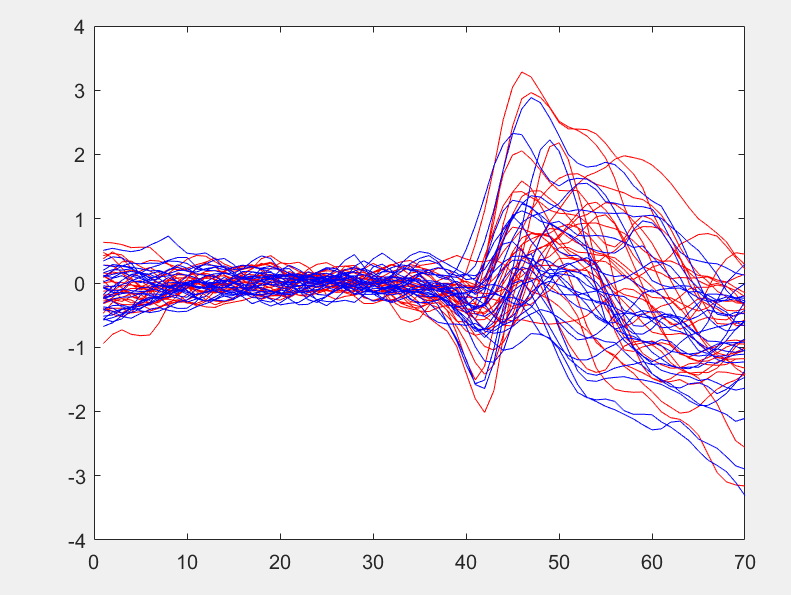
I have an experiment in which it was done under two conditions. For each condition, the experiment was performed 26 times. The output of the experiment is a plot with 70 time indices. I would like to train a classifier to predict, given a plot, to which condition it belongs. The image below shows the output of the conducted experiment under the two conditions recognised by different colors. The actual experiment begins at index 35, and thus it can be seen there is no difference in the outcome of the experiment before that regardless of the condition. The plots represent power spectral density of EEG from one channel (electrode).
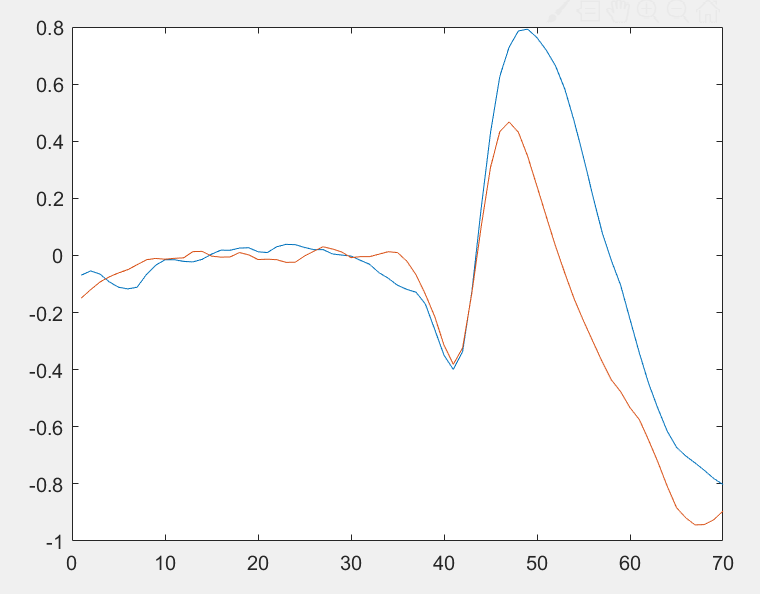
I am trying to train an svm classifer ignoring the features below 35. The classifier is having hard time doing so considering the high variability of each condition. One thing is, averaging the red plots and blue plots yield a noticeably different behaviour, as can be seen from the second figure. I would like to improve the accuracy of my classifier, beyond 65%. Is LSTM suitable for this type of problem? Any other suggestions?