I have a dataset that comprises 76 countries, and 6 columns of distinct quantitative variables, which are the mean values of that variable relative to each country:
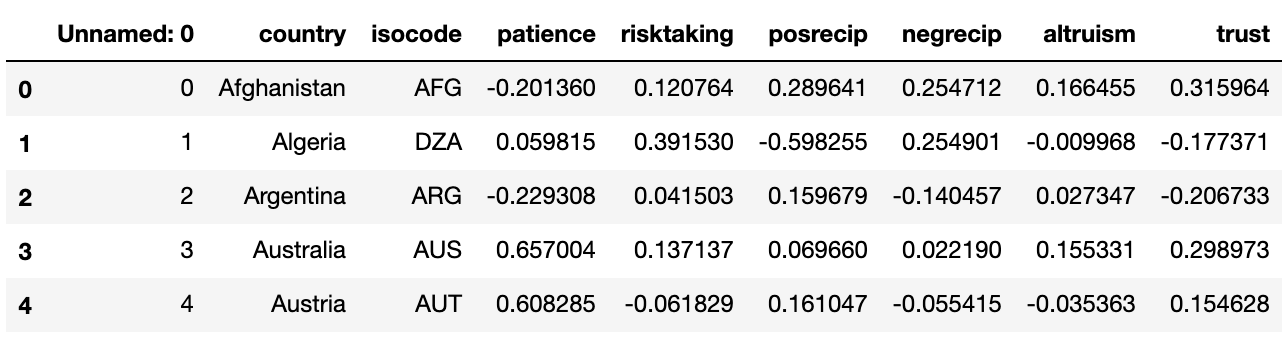
If I were to take a random sample of the 6 variables - an individual within one of the countries - how would I best go about predicting to which country that individual belongs?
I have a whole separate dataset, with thousands of data points, so I know which country the data belongs to and can thus know for certain whether the algorithm is predicting accurately.
Thus far I have been looking at decision trees and random forest options, but none of the example use cases I've seen translate very well to what I am trying to do. Perhaps I'm looking in the wrong place.
It's not predicting the behavior, as the behavior is already known...it's more about predicting to which country-classification the behavior belongs. Ideas? Comments?