I am using an imbalanced dataset (rare positive cases) to learn models for prediction and the final good AUC is 0.92 but the F1 score is very low0.2.
Is it possible to add some key features which will change the class probabilistic distribution and thus we can get a threshold to generate a higher F1?
Here is an example:
In my original model, I get a class probabilistic distributions shown below:
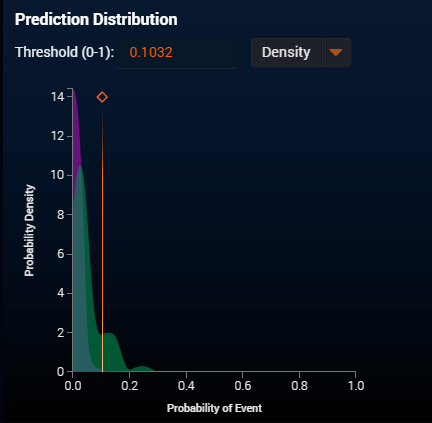
I can adjust the threshold to make a better precision but meanwhile cut some recall off. It is due to the large overlapping area between two distributions.
Then I use an extreme dataset, i.e. include the target itself as a feature to learn. As a result, I can see I split the distribution completely disjointed. 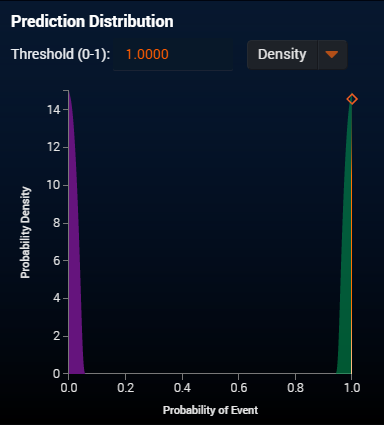
Dose it mean if I introduce a strong feature, I can split the distribution to some extent and thus promote the precision and thus f1 score? Or please advise how to improve precision under imbalanced classification issue.
Many thanks