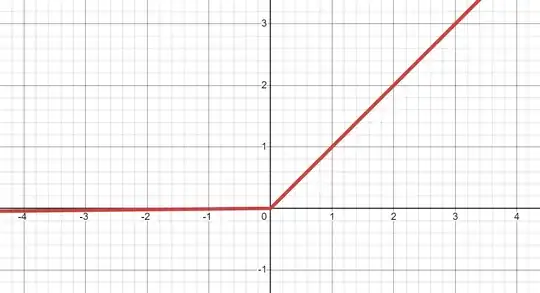
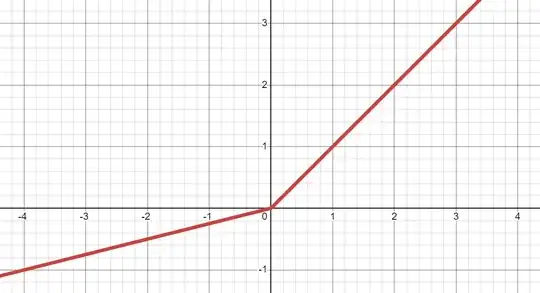
I thought both, PReLU and Leaky ReLU are: $$f(x) = \max(x, \alpha x) \qquad \text{ with } \alpha \in (0, 1)$$
Keras, however, has both functions in the docs.
Leaky ReLU
return K.relu(inputs, alpha=self.alpha)
Hence (see relu code): $$f_1(x) = \max(0, x) - \alpha \max(0, -x)$$
PReLU
def call(self, inputs, mask=None):
pos = K.relu(inputs)
if K.backend() == 'theano':
neg = (K.pattern_broadcast(self.alpha, self.param_broadcast) *
(inputs - K.abs(inputs)) * 0.5)
else:
neg = -self.alpha * K.relu(-inputs)
return pos + neg
Hence: $$f_2(x) = \max(0, x) - \alpha \max(0, -x)$$
Question
Did I get something wrong? Aren't $f_1$ and $f_2$ equivalent to $f$ (assuming $\alpha \in (0, 1)$?)