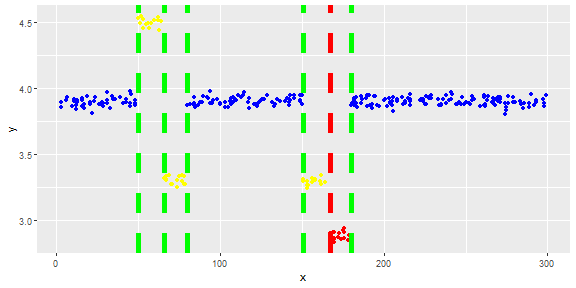
I have a vector and want to detect outliers in it.
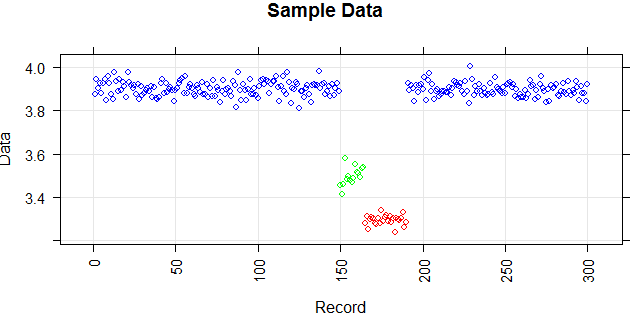
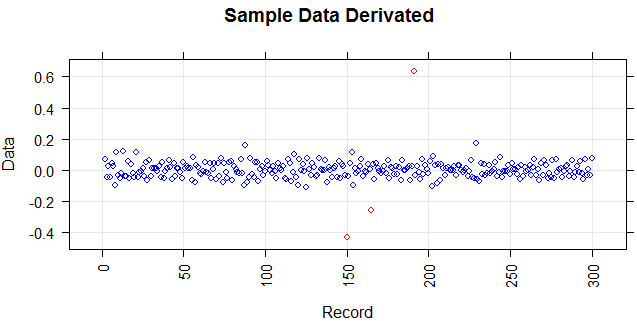
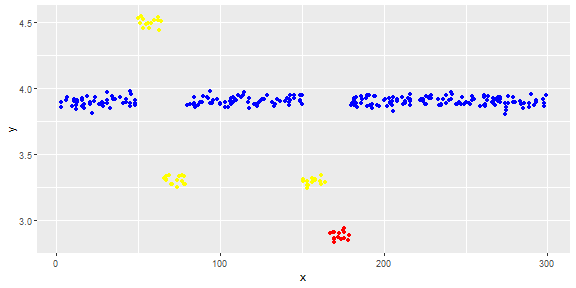
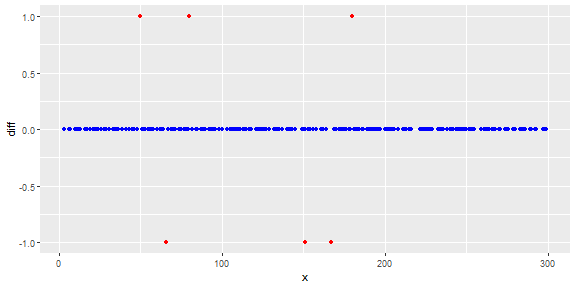
The following figure shows the distribution of the vector. Red points are outliers. Blue points are normal points. Yellow points are also normal.
I need an outlier detection method (a non-parametric method) which can just detect red points as outliers. I tested some methods like IQR, standard deviation but they detect yellow points as outliers too.
I know it is hard to detect just the red point but I think there should be a way (even combination of methods) to solve this problem.
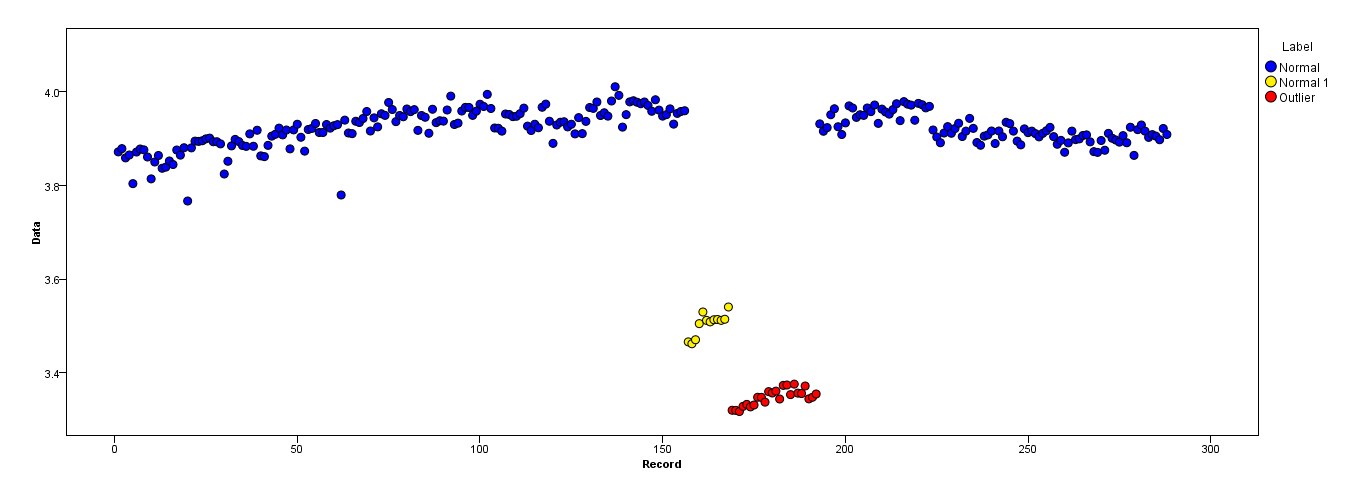
Points are readings of a sensor for a day. But the values of the sensor change because of system reconfiguration (the environment is not static). The times of the reconfigurations are unknown. Blue points are for the period before reconfiguration. Yellow points are for after the reconfiguration which causes deviation in the distribution of the readings (but are normal). Red points are results of illegal modifying of the yellow points. In other words, they are anomalies which should be detected.
I'm wondering whether the Kernel smoothing function estimate ('pdf','survivor','cdf',etc.) could help or not. Would anyone help about their main functionality (or other smoothing methods) and justification to use in a context for solving a problem?