I try to make some credit score task. I stuck in conceputal problem.
There is:
train_data (62 columns, 10339239 rows, 1250000 unique ID values [0 - 1249999]([min-max] ID values))
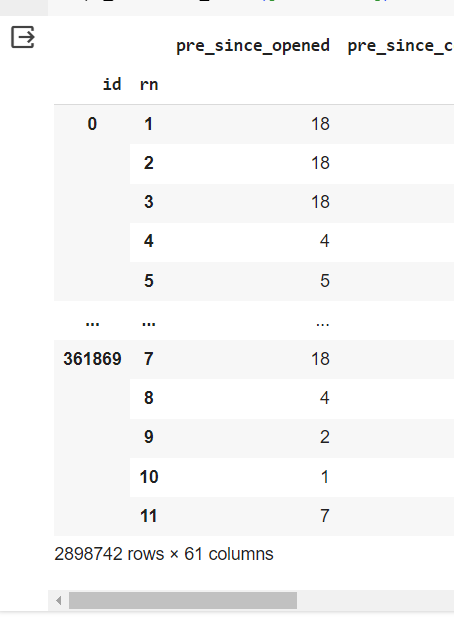
test_data (62 columns, 4724601 rows, 500000 unique ID values [3000000 - 3499999]([min-max] ID values))
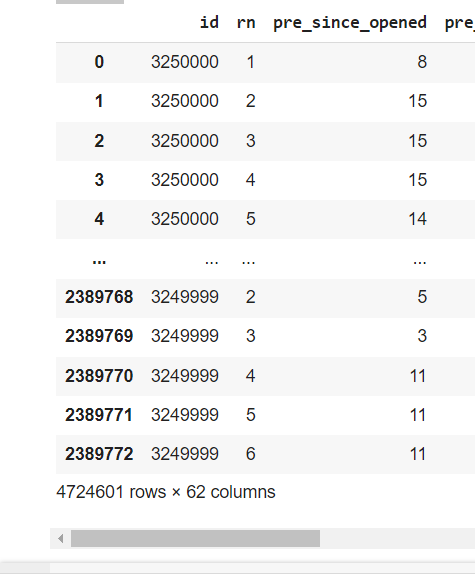
train_target.csv (2 columns: ID and flag (flag is target variable, must be predicted), with 361870 rows, all with unique ID, [0 - 361869]([min-max] ID values))
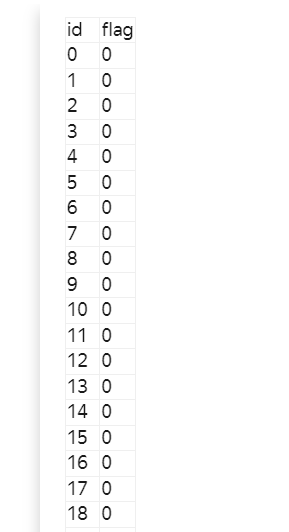
test_target.csv (1 column: ID, 500000 rows, all ID is unique, [3000000 - 3499999]([min-max] ID values))
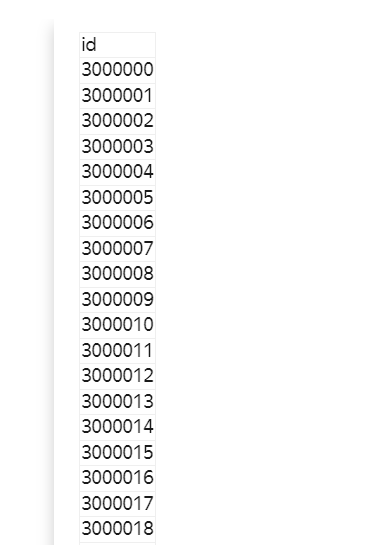
Need to obtain scores in range [0,1] for test_target.csv.
train_data and test_data has 62 columns, ID, RN, ... . Both of them are corresponds time (if datetime bigger, then RN bigger in one ID value). ID means request for credit/loan, RN means number of credit/loan in credit history. FLAG in train_target.csv means: 1-default/bankruptcy.
I have no idea, how to train model for this data. I tried to use XGBoost. Trained model has to take few records ordered by RN with same ID and give one answer FLAG in range [0, 1]. how can this be done? XGBClissifier? or regressor? Throug train_test_split or TimeSeriesSplit? Can u give me advice, please?
How to apply TimeSeriesSplit on train data?