I have a Random forest model that tries to predict what kind of a useful activity a machine is doing based on its power readings. There are 5 features in a single reading.
There are two main types of activities: Main (A set of useful activities. There are 6 such such activities.) and idle (the machine is not doing a useful activity).
Using an if-else method, I find whether a reading was generated by a main activity or an idle activity. Next, if the reading is from a main activity, I use the Random forest model, which has been trained with readings of main activities, to find the type of the main activity.
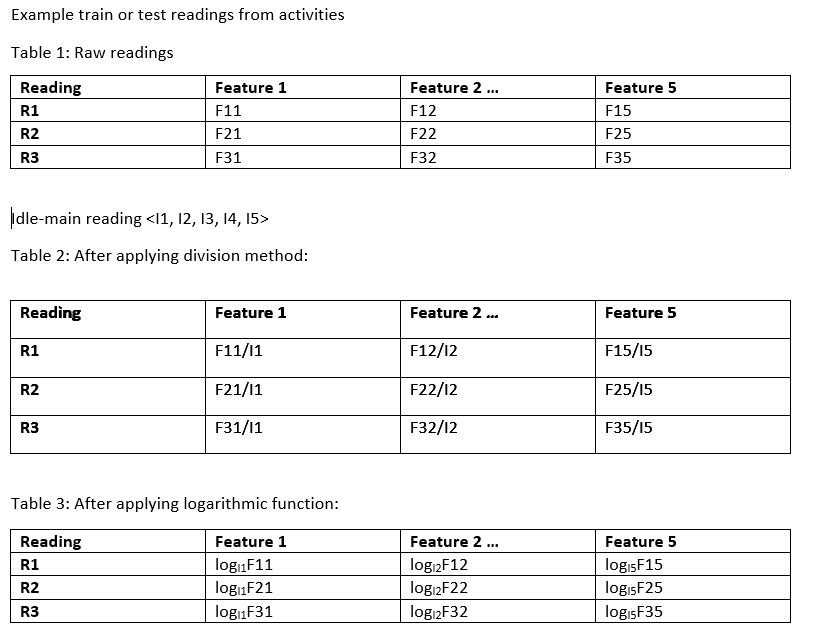
I trained the model with raw readings (Table 1 in figure) of main activities. But the model yielded poor results against the test data.
Then, I divided all the readings in the training dataset (which has only readings from main activities) by the mean of idle readings (let's call this idle-mean reading), and trained the Random forest with that (Dataset in Table 2). That also did not work well (I also divided the test data by the idle-mean reading).
Finally, I applied the logarithmic function to the training and test data. Here, each value in the dataset is replaced by the logA(B) where A (base) is the is the idle-mean reading and B (argument) is the reading (Table 3).
This yielded very good results. I tested it again and again with several test data sets.
My question: Can someone please explain why this works? My conceptual knowledge in ML is not great, so I'm having a hard time explaining this.