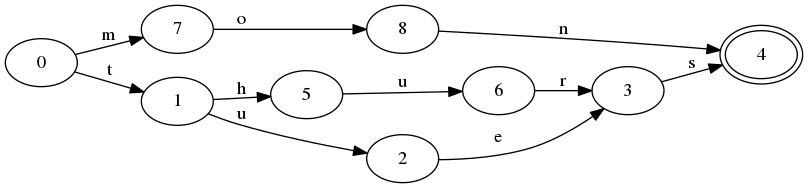
From my reading it seems that most grammars are concerned with generating an infinite number of strings. What if you worked the other way around?
If given n strings of m length, it should be possible to make a grammar that will generate those strings, and just those strings.
Is there a known method for doing this? Ideally a technique name I can research. Alternatively, how would I go about doing a literature search to find such a method?