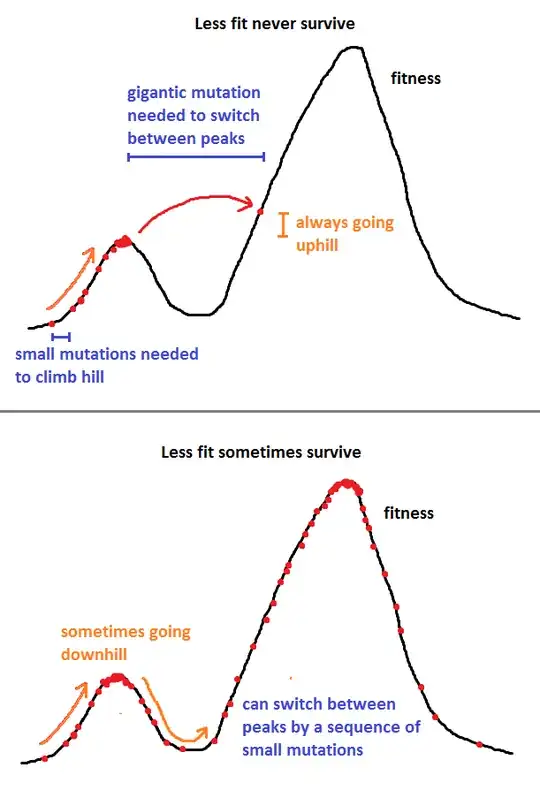
Nick Alger's answer is very good, but I'm going to make it a little more mathematical with one example method, the Metropolis-Hastings method.
The scenario that I'm going to explore is that you have a population of one. You propose a mutation from state $i$ to state $j$ with probability $Q(i,j)$, and we also impose the condition that $Q(i,j) = Q(j,i)$. We will also assume that $F(i)>0$ for all $i$; if you have zero fitness in your model, you can fix this by adding a small epsilon everywhere.
We will accept a transition from $i$ to $j$ with probability:
$$\min\left(1, \frac{F(j)}{F(i)}\right)$$
In other words, if $j$ is more fit, we always take it, but if $j$ is less fit, we take it with probability $\frac{F(j)}{F(i)}$, otherwise we try again until we accept a mutation.
Now we'd like to explore $P(i,j)$, the actual probability that we transition from $i$ to $j$.
Clearly it's:
$$P(i,j) = Q(i,j) \min\left(1, \frac{F(j)}{F(i)}\right)$$
Let's suppose that $F(j) \ge F(i)$. Then $\min\left(1, \frac{F(j)}{F(i)}\right)$ = 1, and so:
$$F(i) P(i,j)$$
$$= F(i) Q(i,j) \min\left(1, \frac{F(j)}{F(i)}\right)$$
$$= F(i) Q(i,j)$$
$$= Q(j,i) min\left(1, \frac{F(i)}{F(j)}\right) F(j)$$
$$= F(j) P(j,i)$$
Running the argument backwards, and also examining the trivial case where $i=j$, you can see that for all $i$ and $j$:
$$F(i) P(i,j) = F(j) P(j,i)$$
This is remarkable for a few reasons.
The transition probability is independent of $Q$. Of course, it may take us a while to end up in the attractor, and it may take us a while to accept a mutation. Once we do, the transition probability is entirely dependent on $F$, and not on $Q$.
Summing over all $i$ gives:
$$\sum_i F(i) P(i,j) = \sum_i F(j) P(j,i)$$
Clearly $P(j,i)$ must sum to $1$ if you sum over all $i$ (that is, the transition probabilities out of one state must sum to $1$), so you get:
$$F(j) = \sum_i F(i) P(i,j)$$
That is, $F$ is the (unnormalised) probability density function for which states the method chooses. You are not only guaranteed to explore the whole landscape, you do so in proportion to how "fit" each state is.
Of course, this is only one example out of many; as I noted below, it happens to be a method which is very easy to explain. You typically use a GA not to explore a pdf, but to find an extremum, and you can relax some of the conditions in that case and still guarantee eventual convergence with high probability.