The question asks to write a regex to the following language $L$ above $\Sigma = \left \{0,1 \right \}$.
$L = \{ w \mid w \in \Sigma^* \text{ and each substring } u \text{ of } w \text{ where } |u| = 4 \text{ contains the character } 0 \}$
Note that if $ |w| \leq 3$ then there is no substring of length 4, so there is no need for the string to contain 0.
I came up with the following regular expression:
$r = (0 \Sigma^3 + \Sigma 0 \Sigma^2 + \Sigma^2 0 \Sigma + \Sigma^3 0)^* (\epsilon + \Sigma + \Sigma^2 + \Sigma^3) : \Sigma = (0 + 1)$
It is a wrong answer because for example the word $0111101$ can be generated by $r$.
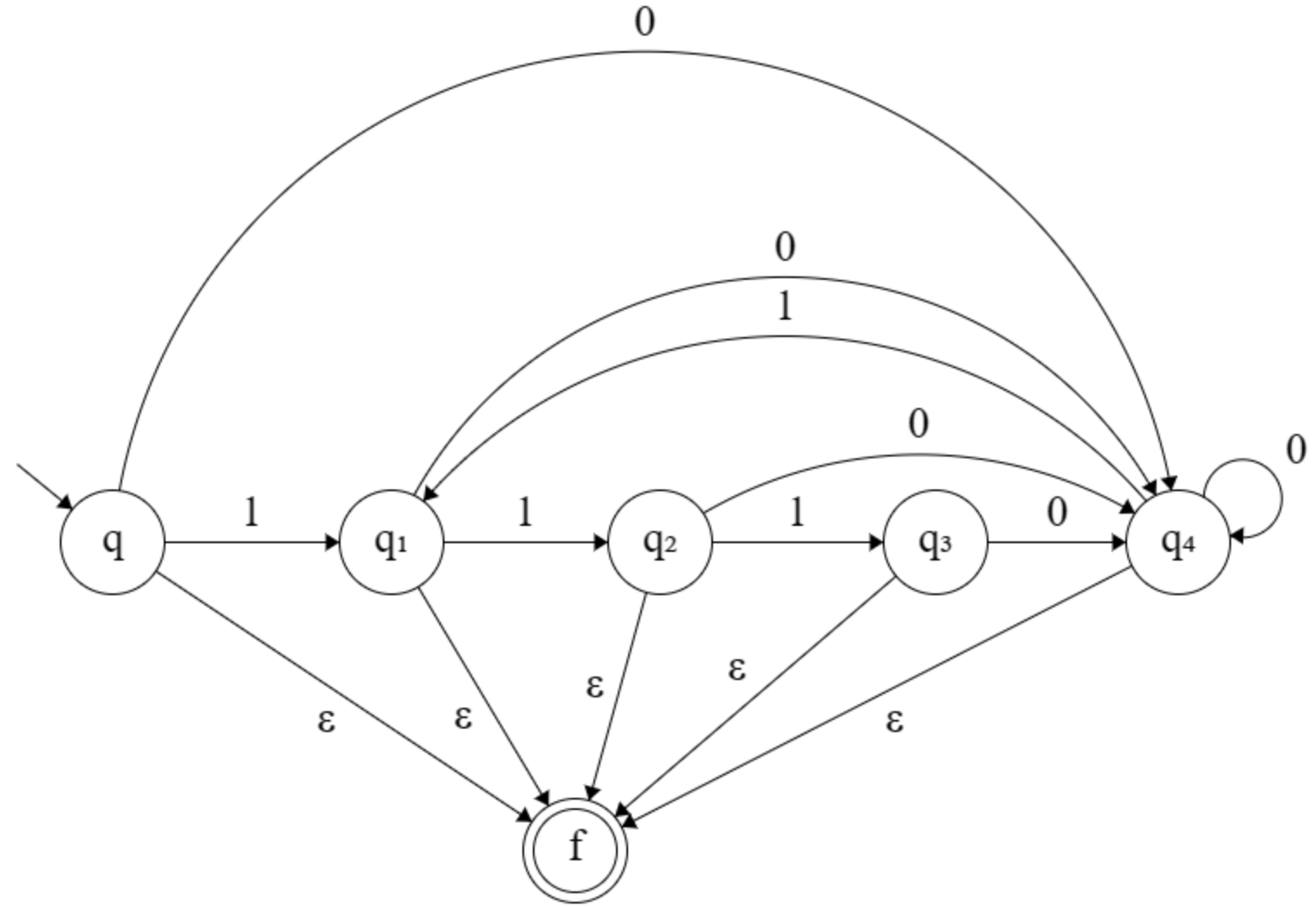
I tried to convert the NFA in the picture to regex, but the regex was too long and it's missing the point of the question because I suppose to generate the regex by understanding what characteristic a word in $L$.
I came up to the conclusion that words in $L$ can't have sustring $1111$ but I don't know how to use it in order to create a regex.
It seems I'm failing short from the solution and I would like to know how I can transform $r$ to the required regex.
 $L$" />
$L$" />