I am confused about how denormalized numbers work in floating point representation.
I was referring to Stallings book and this article. The book initially explains floating point number format in general and then explains IEEE 754 floating point format. I will tell explicitly when I am talking about floating point format in general and when about IEEE 754.
First let me tell you what I understand. Lets consider single precision (32 bit) numbers. As shown in the book, the normalized numbers in IEEE 754 takes following form:

In both general and IEEE 754 floating point number,
- Sign bit is 0 for positive number, 1 for negative number.
- Fraction aka significand has implicit leading 1.
- Biased component is exponent with bias 127.
With this information, I am able to come p with range of normalized numbers in IEEE 754 standard. Its $\pm2^{-126}$ to $(2-2^{-23})\times 2^{127}$ as given in that article. This is how I interpret, how its derived.
- Max significand: $(1.\underbrace{11..11}_{23\text{ bits}})_2=(2-2^{-23})_{10}$
- Min significand: $(1.\underbrace{00..00}_{23\text{ bits}})_2=(1)_{10}$ and is simply omitted from multiplication to $\pm2^{-126}$
- Min exponent: Biased: $(00000001)_2=(1)_{10}$, Unbiased: $1-127=-126$
- Max exponent: Biased: $(11111110)_2=(254)_{10}$, Unbiased: $254-127=127$
I know that significand in de-normalized range does not have implicit leading 1 and in fact has leading 0.
Doubts
I have following doubts about denormalized range in IEEE 754 format:
As give in that article, how is the denormalized single precision range is $\pm 2^{-149}$ to ${(1-2^{-23})\times2^{-126}}$
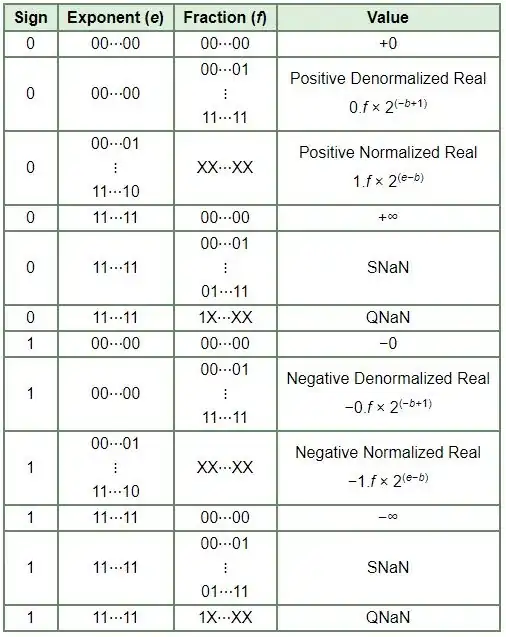
Consider below table from Stallings book. In this, in the biased exponent column, entries for positive and negative denormalized (last two) rows is $0$, but in the value column, the exponent of $2$ is $e-126$, even though there is no $e$ elsewhere in those rows.
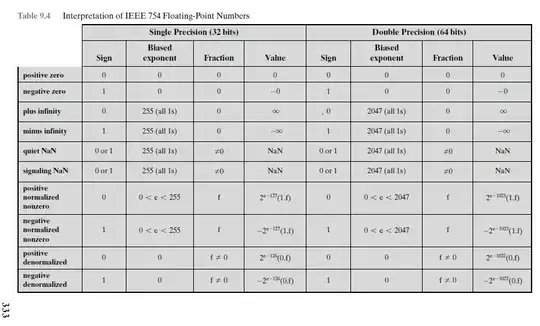
Now consider the below table given under summary section of that article. Note that in 2nd row and 5th last row of denormalized real, "Exponent" column says $00..00$, however in value column, there is $+1$ in the exponent: $2^{(-b\color{red}{+1})}$. From where this $+1$ came?
How exponents in the book (as explained in the question 2) and the exponent in the article (as explained in the question 3) compare and how they lead to the range asked in question 1?