I think, what you are looking for is $d_k = d_v = d_{model}/h$ [1] where $h$ number of heads and $d_{model}$ dimensions of keys, values and queries for single attention version of the model. In relation of the model architecture and its embedding specifically, the above translates to
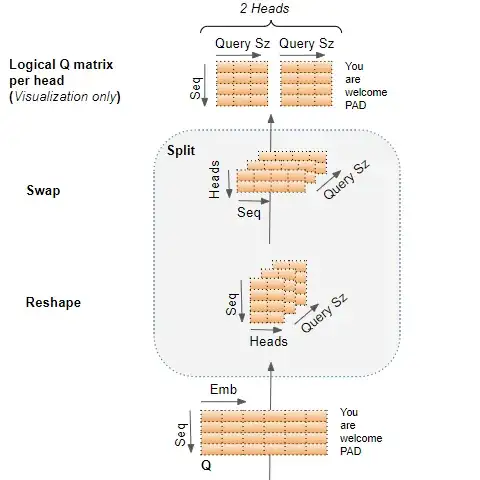
$Query Size = Embedding Size / h$
Model input
According to the above, at the input embedding layer weights for each head are stacked together in the single embedding matrix. Stacking together, hmm.. (stacking, ensembling).

Per head scores
As in the normal self-attention, attention score is computed per head but given the above, these operations also take in place as a single matrix operation and not in a loop. The scaled dot product along with other calculations take place here.
Multi head merge
As a final step, the attention score of each head is merged by simply reshaping the full attention score matrix so that the per-head attention scores are concatenated into a single attention score.
Summing it up
With a clearer view of what the architecture of the model is and how its computational graphs looks like, we can go back to your original questions and say:
The multi-headed model can capture richer interpretations because the embedding vectors for the input gets "segmented" across multiple heads and therefore different sections of the embedding can attend different per-head subspaces that link back to each word.
In a more general sense, one can argue that running through the scaled dot-product attention multiple times in parallel and concatenating is a form of ensembling.
I hope it helps. For more details about the several operation taking place in the transformer architecture, I suggest you have a look at this post from which my answer is heavily influenced from:
https://towardsdatascience.com/transformers-explained-visually-part-3-multi-head-attention-deep-dive-1c1ff1024853
[1] 3.2.2 https://arxiv.org/pdf/1706.03762.pdf

