So, I have tried all the different activation functions listed on https://keras.io/api/layers/activations/. I can indeed approximate any nonlinear function in the training range perfectly well - but for any data outside the training range, I have a model that is limited to linear functions. For example, I tried to approximate the sinus function and had great results within the training range but was left with a linear function outside this range. I used a network with 3 hidden ReLU layers(with 16 units per layer) and an affine output layer. Here is the good approximation within the training range:
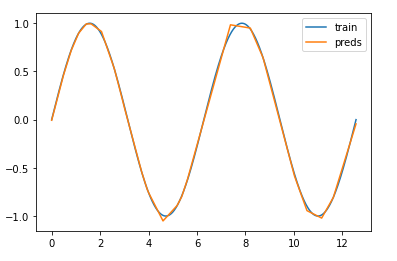
and the predictions outside the training range:
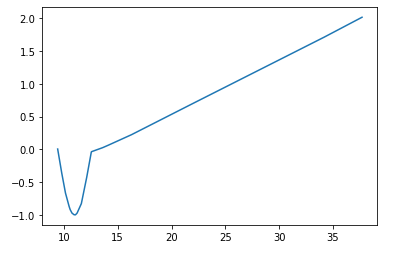
The same appends when trying to approximate any other nonlinear function. This is unfortunate because you would rather want your model to generalize well than to perform good exclusively on training data :( I could of course use a sine explicitly as an activation function but that seems to ridicule(maybe a strong word but you get the idea) the "self-learning" of neural networks.
This seems to make neural networks look very limited in my eyes - am I missing something?
I really appreciate your time!