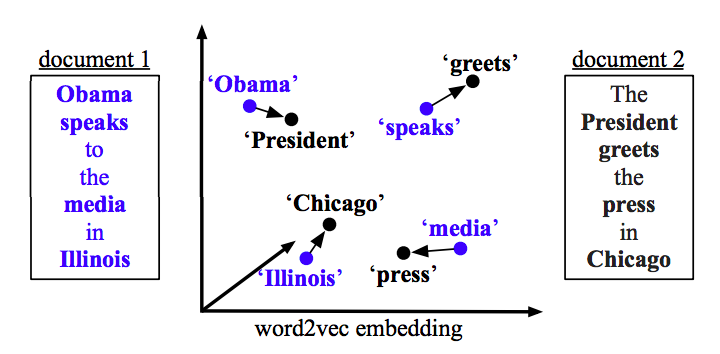
I'm trying to calculate similarity between texts with various lengths. My current approach is following:
- Using Universal Sentence Encoder, I convert text to a set of vectors.
- I average these vectors to create the final feature vector.
- I compare feature vectors using cosine similarity.
This gives me pretty good results for texts with roughly same sizes, but I was wondering if there is a better approach for the step #2 if texts have different lengths.