Zeroing weights disables them. Yes, there are various applications of zero tensors (such as convex cost functions as you mention). Let's take the case of Neural Nets (NNs) and see if the math gives us more intuition:
$$
tensor\div0 = undefined\\
tensor * 0 = 0\\
tensor \cdot 0 = 0\\
$$
Example Graph #1: How would one disable a single synapse connected to the output layer?
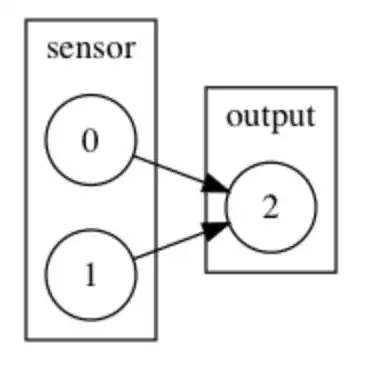
Math Example: Let $X$ be an input tensor of shape (1,2). Let $W$ be a weight tensor of shape (2,1). The dot product is represented here by the $\cdot$ symbol.
If all elements in tensor $W$ are zero:
$$
\begin{align*}
X = \begin{matrix}[1&1]\\ \end{matrix}\ \ \
W = \begin{matrix}[0]\\ [0]\end{matrix}\
\end{align*}
$$
$$
X \cdot W = [0]\\
$$
If all elements in tensor $W$ are randomly initialized (between -1 and 1):
$$
\begin{align*}
X = \begin{matrix}[1&1]\\ \end{matrix}\ \ \
W = \begin{matrix}[0.24660266]\\ [0.05121049]\end{matrix}\
\end{align*}
$$
$$
X \cdot W = [0.29781315]\\
$$
If one element in tensor $W$ is randomly set to zero:
$$
\begin{align*}
X = \begin{matrix}[1&1]\\ \end{matrix}\ \ \
W = \begin{matrix}[0]\\ [0.05121049]\end{matrix}\
\end{align*}
$$
$$
X \cdot W = [0.05121049]\\
$$
Aha, some intuition! Set an element of your weight vector $W$ to zero to disable it.
Example Graph #2: As complexity scales, so too does our potential loss of control over architecture.
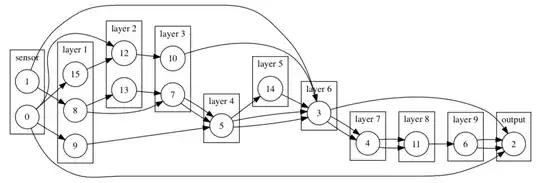
When you need to tweak the details, it is important to have tools to change nodes and edges on a per unit basis. Zero weighting gives you that ability.
This idea generalizes to CNNs, GANs, RNNs, etc. Look at the particular algorithm and go layer by layer. What are the designers trying to accomplish?