I am doing a geospatial assessment integrated with ML modeling. The problem is the very low accuracy percentage, as more training features increases, it gets lower. What could be the solution to such a problem?
Accuracy test: 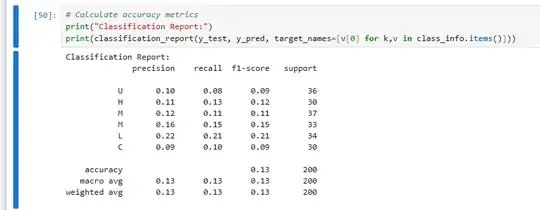
Sample of training data:

CODE:
ndti_path = r'\try2.tif'
train_path = r'trainGPKG.gpkg'
Read training data - through geopandas
train_gdf = gpd.read_file(train_path)
X = [] # Features (NDTI values)
y = [] # Labels (class IDs)
for idx, row in train_gdf.iterrows(): #iterates over each polygon
geom = row.geometry
class_id = row['macroclass_id']
# Convert polygon to pixel mask
mask = rasterio.features.geometry_mask(
[geom],
out_shape=ndti.shape,
transform=transform,
invert=True
)
# gget NDTI values inside the polygon
values = ndti[mask]
values = values[~np.isnan(values)] # Remove NaN valuees
if len(values) > 0:
### statistics for each polygon
X.append([
np.mean(values),
np.std(values),
np.median(values),
np.min(values),
np.max(values)
])
y.append(class_id)
rf = RandomForestClassifier(
n_estimators=100,
random_state=42,
class_weight='balanced'
)
rf.fit(X, y)
classified = np.zeros(ndti.shape, dtype=np.uint8)
rows, cols = ndti.shape
for i in range(1, rows-1):
for j in range(1, cols-1):
window = ndti[i-1:i+2, j-1:j+2]
values = window.flatten() #Clean Data, convorts into 1D array and remove NaN values
values = values[~np.isnan(values)]
if len(values) > 0:
features = [ ##Compute features if valid pixels exist
np.mean(values),
np.std(values),
np.percentile(values, 25),
np.percentile(values, 75),
len(values)
]
classified[i,j] = rf.predict([features])[0]