A typical way to calculate $R^2$ involves a ratio of residual to total variance.
$$
R^2 = 1-\dfrac{
\text{
Residual variance
}
}{
\text{
Total variance
}
}
$$
If you remove an outlier, you may decrease the total variance an enormous amount without getting a large reduction in residual variance. In that case, removing the outlier will decrease the $R^2$.
Given the comment that MSE (related to residual variance) decreases while $R^2$ also decreases, I find this explanation to be very likely.
Let's look at a simulation.
library(MASS)
library(ggplot2)
set.seed(2024)
Let's simulate data with a weak correlation but no outliers
N <- 999
XY <- MASS::mvrnorm(
N,
c(0, 0),
matrix(c(
1, 0.3,
0.3, 1
), 2, 2)
)
d1 <- data.frame(
x = XY[, 1],
y = XY[, 2],
Set = "No Outliers Present"
)
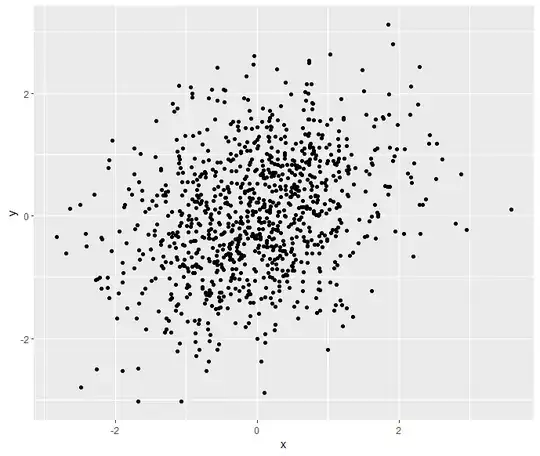
Check out the plot
ggplot(d1, aes(x = x, y = y)) +
geom_point()
Tack on an outlier, say a giraffe (to borrow an idea from another answer)
d2 <- data.frame(
x = c(XY[, 1], 99),
y = c(XY[, 2], 101),
Set = "Outlier Present"
)
Check out the plot
ggplot(d2, aes(x = x, y = y)) +
geom_point()
Fit linear regressions with and without the outliers
L1 <- lm(d1$y ~ d1$x)
L2 <- lm(d2$y ~ d2$x)
Print summaries of the regressions and the data
R^2
summary(L1)$r.squared # I get R^2 = 0.09568171 without the outlier
summary(L2)$r.squared # I get R^2 = 0.8828702 with the outlier
Total variance
var(d1$y) # I get a total variance in y of 0.9963245 without the outlier
var(d2$y) # I get a total variance in y of 11.1925 with the outlier
Residual variance
var(resid(L1)) # I get a residual variance of 0.9496832 without the outlier
var(resid(L2)) # I get a residual variance of 1.310975 with the outlier
Without the outlier, there is a weak but existent realtionship between the two variables.
With the outlier, there is a much stronger relationship between the two variables.

Despite the fact that the $R^2$ with the outlier is much higher, however, it has a higher residual variance. This is because the total variance is so much higher when there is an outlier. Just look at how much more spread out the data are when the outlier is included.

