Brief Summary
Yes, a wider-range-variable would dominate the single linkage clustering without scaling.
Explanation
The tendency of wider-range-variables to dominate the clustering does not only apply to hierachical clustering, but to many clustering methods.
The reason for this lies below the clustering: most (if not every) clustering algorithm is based on a distance metric. If not otherwise specified, the euclidean distance is typically uses. And this metric is dominated by the wide-range variables. Hence, the clustering algorithms that rely on such a metric, are as well dominated by the wider-range-variables.
Normalizing is the easiest way to handle this problem (if it is a problem). Using different metrics would be another way. E.g. the Mahalanobis distance does kind of a normalization by it self. Another approach would be a custom metric that uses some domain knowledge.
Example
Do demonstate this, I created a example dataset with
- wide-range y-axis and small-range x-Axis (left column)
- normalized features (right column)
And clustered it with
- complete linkage (top row)
- singale linkage (bottom row)
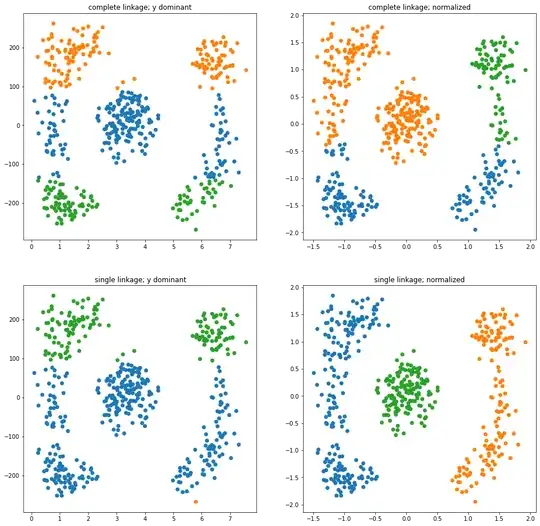
As you can see, the non-normalized data (left column) is clustered nearly exclusivly by the y-value.
You also see that the complete linkage prefers compact clusters (top row, both columns), while the single linkage avoids bigger gaps (bottom row, right image)
