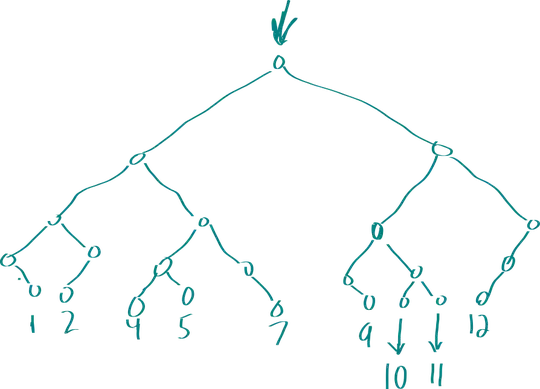
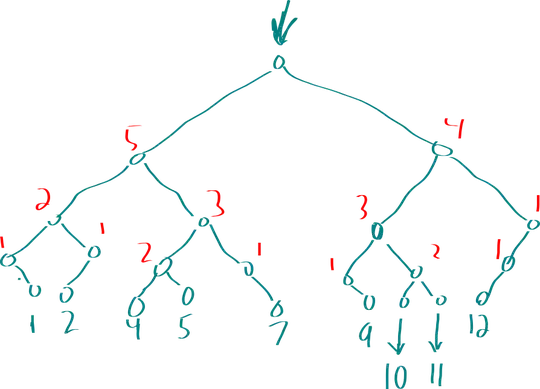
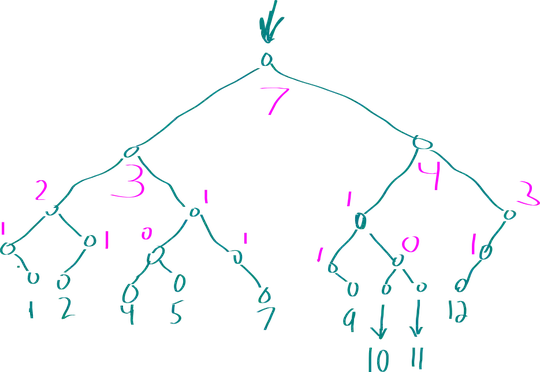
I stumbled upon this question looking for a more practical answer, so here is a more hands-on
solution using Java code and 32-bit integers as example. The basic idea is to take an array
$\left[0, 1, ... m-1\right]$, shuffle it, and return the first $n$ entries. The go-to shuffling
algorithm is Fisher-Yates which
can be stopped early, making our solution even more efficient. This leads to the following code:
int[] randIntsUniqDense( RandomGenerator rng, int m, int n )
{
assert m >= n;
var samples = IntStream.range(0,m).toArray();
// Partial Fisher-Yates shuffle
for( int i=0; i < n; i++ ) {
int j = rng.nextInt(i,m);
// swap i <-> j
int sample = samples[j];
samples[j] = samples[i];
samples[i] = sample;
}
// Return requested number of samples
return Arrays.copyOf(samples,n);
}
The implementation above requires $\mathcal{O}(m)$ operations due to the large samples array
that we have to build. But it turns out we can do better. Instead of keeping track of the entire
samples array, we can only keep track of the changes using a Hash Table.
The following randIntsUniqSparse() method behaves identical to randIntsUniqDense() while only
requiring $\mathcal{O}(n)$ operations:
int[] randIntsUniqSparse( RandomGenerator rng, int m, int n )
{
assert m >= n;
var results = new int[n];
var changes = new HashMap<Integer,Integer>();
// Partial Fisher-Yates shuffle
for( int i=0; i < n; i++ ) {
int j = rng.nextInt(i,m);
// swap i <-> j
var sample = changes.remove(j);
if( sample == null )
sample = j;
if( i < j ) {
var displaced = changes.remove(i);
if( displaced == null )
displaced = i;
changes.put(j,displaced);
}
results[i] = sample;
}
return results;
}
To accurately answer the question, we now have to check that randIntsUniqSparse can be generalized to arbitrary-length
integers, using at most $\mathcal{O}(n*log(m))$ operations. The answer is yes, assuming that rng.nextInt(i,m) is an
$\mathcal{O}(log(m))$ operation. That assumption may not be valid for pseudo-RNGs if the desired bits
of randomness increase with $m$. Instead, You could use a Hardware RNG.