I'd like to expand upon Anton's comment in his answer, and provide an explicit answer to the situation posed by Ashwin in the comments. I think it'll be helpful to answering the primary question.
Let's consider the situation
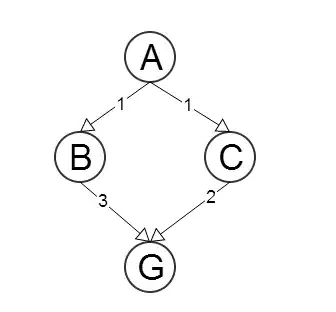
Where A is the starting node and G is the goal node. The numbers on the nodes are the heuristic costs, while the numbers on the edges are the costs to travel between those two nodes.
We can see that the heuristic function is admissible (i.e it doesn't overestimate the cost of reaching the goal) and consistent (ie. it decreases as we get closer to the goal node).
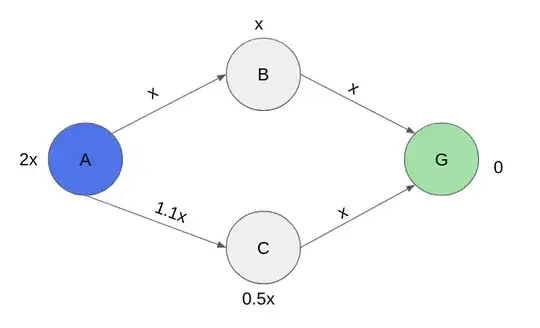
Here's how the A* algorithm would find the optimal solution for this graph:
Iteration 1: It checks the f(x) for all of A's neighbours
- f(B) = x + x = 2x
- f(C) = 1.1x + 0.5x = 1.6x
Since f(C) is smaller, it picks C as the next node.
Iteration 2: Check f(x) for C's neighbours and the existing paths
- f(B) = x + x = 2x (A->B)
- f(G) = 2.1x + 0 = 2.1x (C->G)
Clearly, the path from A->B is cheaper and thus A* will shift its focus to that path.
Iteration 3: Check f(x) for B's neighbours and the existing paths
- f(G) = 2x + 0 = 2x (B->G)
- f(G) = 2.1x + 0 = 2.1x (C->G)
Since B->G is cheaper here and we've reached the goal node (plus traversed all paths), the algorithm ends with the (optimal) solution A -> B -> C.