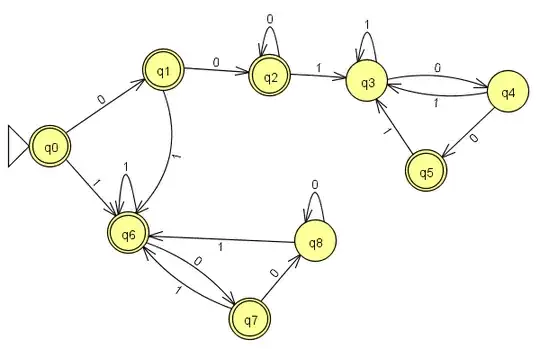
I was wondering when languages which contained the same number of instances of two substrings would be regular. I know that the language containing equal number of 1s and 0s is not regular, but is a language such as $L$, where $L$ = $\{ w \mid$ number of instances of the substring "001" equals the number of instances of the substring "100" $\}$ regular? Note that the string "00100" would be accepted.
My intuition tells me it isn't, but I am unable to prove that; I can't transform it into a form which could be pumped via the pumping lemma, so how can I prove that? On the other hand, I have tried building a DFA or an NFA or a regular expression and failed on those fronts also, so how should I proceed? I would like to understand this in general, not just for the proposed language.